在目前的工作中我有一套神乎其技的办法能够在缺失数据的情况下推算出数天前,甚至于数月前的25片wafer分别在GSD的tool里面具体的位置。
这个神技是有缺点的,为了提高置信度,有几个假设是需要满足的,这也就是一些边界条件:
- 必须有25片wafer在盒子里面(大部分情况下满足)
- 盒子里面只有25个slot(大部分情况下满足)
- 每次被传出的wafer只能为1片(大部分情况下满足)
- wafer被传回前不能有再次传出wafer(对于管理严格的Fab,记录详实的情况下)
- 短程N片wafer之内的顺序信息不被打乱,2<N<25.(例如2-4-7-8-6,N=5,五片wafer只会有镜像的顺序6-8-7-4-2,其内部顺序信息不被打乱,大部分情况下的工艺满足)
对于算法的输入数据需要:
- GSD的Batch Count:13(8in)或者17(6in)
- 每次进入GSD时具体的Batch里面包含多少片wafer [N]
- 校验checksum,进出tool的时候记录的lm#,这个用来反正前面的四个边界条件是否被打破
具体的算法:
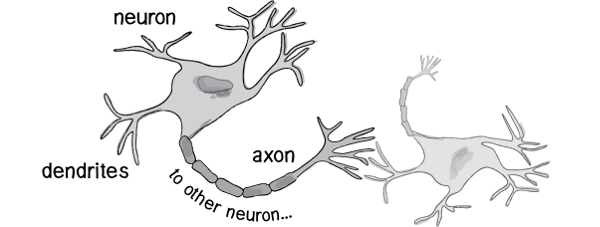
时序上,正向时序中其实我们每次只能处理13片或者17片的具体信息,然后再把多次处理的具体信息按照时序的前后合成25片的也就是一盒信息,这也就是正常的wafer transfer。这种信息处理其实就是一个前级13或者17个“树突”,后面2或者3个“处突”的二级“树突”神经网络,中间由特定的轴突(就理解为算法)连接。每个按照时序的传送都是M-P结构的神经网络,每一级向下一个时序进行计算,满足前面5个边界的计算完全可以模拟出wafer的传送,而因为每一个Tool ID每个时间点只能process一个lot,所以已知process先后顺序的情况下可以用Tool ID替换掉时间轴,时序即Process顺序
而推算最初的wafer的号码,就是一个逆向的神经网络计算B-P算法,通过最后一级的信息来最终逆向工程,还原13或者17个树突的信号。这最后一级的信息可能来自于最后一次OCR的数据我们通过Klarity就能获得,也可能是我们自己打开盒子查看wafer的具体顺序信息,极端情况下可能只能获得部分顺序信息,这是我们就充分利用前面的边界条件来回归原本的顺序信息。




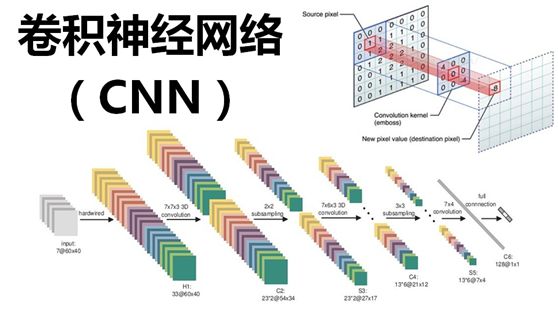
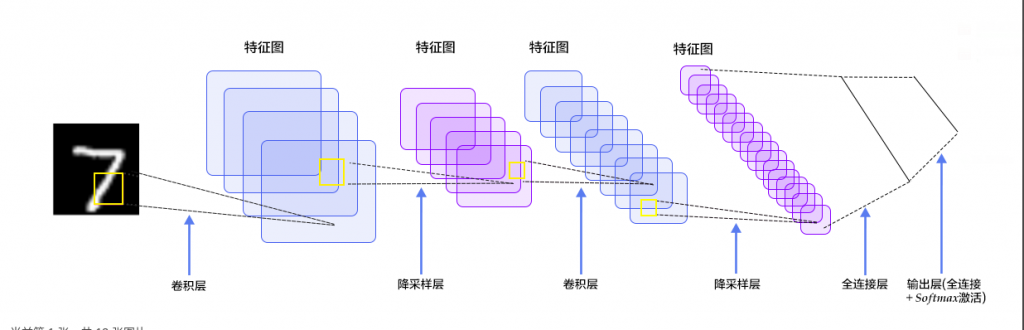
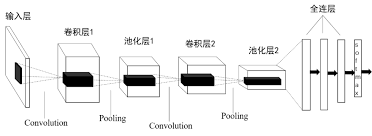
讲完严格的边界条件以及边界条件对算法的完善,我们来看看算法本身。之前的两个lot的wafer排列完全可以看成两幅画面,我们可以借助卷积神经网络来识别两幅画面对应的“一个整盒25片wafer的顺序”。